




As the number of IoT devices continues to proliferate, the amount of data generated by companies has increased exponentially. However, due to the massive surge of data generation from a massive growth of “smart things”, there is a bottleneck within the traditional cloud computing infrastructure. Therefore, cloud computing is shifting some of its processes to other layers known as fog computing and edge computing for more reliable and real-time processing. In addition, with the adoption of decentralizing traditional computing architecture, the fog and edge layer has allowed machine intelligence to be possible. As a result, fog and edge computing solutions have transformed how IIoT applications collect, process, store, move, and analyze data. Therefore, the benefits of fog computing and edge computing enable companies and organizations to pave the way for their digital transformation faster than ever. This blog will further explain fog computing vs edge computing and their differences.
What is Fog Computing and Edge Computing?
To understand the difference between fog computing and edge computing, we need to understand why cloud computing needs to offload data to the fog and edge layer. Cloud computing, as we know, is in the early stages of IoT development, where IoT and IIoT devices send all of the collected data to a remote data server for additional processing, usually for machine learning. The computers that reside in the cloud data centers are typically massive server computers with powerful resources. These computers are capable of storing huge amounts of data and running complex applications. However, even the cloud is quite overwhelmed with the massive influx of data generated by billions of IoT and IIoT devices. Therefore, cloud computing is offloading some of its operations closer to the data source. Fog computing and edge computing are the extensions of cloud networks that allow IIoT applications to be much faster and powerful. Though fog and edge computing can be similar, there are some distinctions that set them apart.
What is Fog Computing?
Fog computing is a layer that exists between the cloud and the edge. Fog computing works as a filter that processes data at the edge and only sends the most crucial information to the cloud for further analytics and storage. Fog computing will process, filter, manage, and analyze data gathered by various sensors and IIoT devices. The computers that are used for fog computing are called fog nodes. Fog computing offloads the computation task from the cloud down to the local area network (LAN). Therefore, fog computing can enable intelligent applications to run at the edge in real-time by bringing powerful computing at the edge. However, by implementing an additional layer between the cloud and the edge, fog computing is adding complexity to the IoT network architecture.
What is Edge Computing?
Edge computing is the layer located closest to the data source, where sensors are often deployed. Edge computing devices such as IIoT devices, sensors, and actuators are connected right on the running applications. These devices gather and compute data in the same hardware or IoT gateways that are installed at the endpoint. Edge computing can also send data immediately to the cloud for further processing and analysis. Without the need to add an additional layer within the IoT architecture, edge computing simplifies the communication chain and reduces potential failure points.
What are the differences between Fog Computing vs Edge Computing?
Fog computing and edge computing are very similar, with several distinctive differences. Fundamentally, both fog and edge computing are offloading the cloud bandwidth to the edge. However, the main differentiator between fog computing and edge computing is the location where data is processed. Edge computing processes data right in the devices that collect the data. Some edge computing applications do not process data right at the sensors and actuators that collect data. However, the computing is still located relatively close to the data source, such as IoT gateways or even rugged edge computers.
On the other hand, fog computing brought the computing activities to the local area network (LAN) hardware. Fog computing processes and filters data and information provided by the edge computing devices before sending it to the cloud. Fog computing will still be processing the information at the edge but physically farther from the data source and hardware that is collecting the information. Since fog is an additional layer within the IIoT architecture, edge computing can work without fog computing. In contrast, fog computing can’t replace edge computing.
Fog Computing and Edge Computing Architecture

The fog environment communicates with other devices and sensors at the local area network (LAN). With fog and edge computing implemented within the IIoT architecture, all the processing is happening at the edge and only delivers information to the cloud for further analytics and storage. Edge computing typically occurs directly on the sensors and devices deployed at the applications or a gateway close to the sensors. In comparison, fog computing extends the edge computing processes to the processors linked to the LAN or can happen within the LAN hardware itself. Hence, the fog architecture may be physically more distant from the edge architecture, sensors, and actuators. Here is the representation of cloud, fog, and edge architecture.
What are the Advantages of Fog Computing at the Edge?
Now that we know that fog computing is an optional additional layer that is not mandatory for IIoT architecture to work, here are some of the advantages of fog computing that can benefit your IIoT applications:
- Increases efficiency of data traffic and reduce network latency
- Data in the cloud network will be much more organized and less cluttered
- Reduce the amount of cloud storage needed
- Bandwidth volume of data being sent to the cloud is much lower
- Reduce bottleneck risks and improve reliability
- Data aggregation from multiple edge devices into regional stores
- Enhance the ability to handle millions of connected devices
-
Lower costs for large cloud storage and high internet bandwidth
What are the Disadvantages of Fog Computing?
Despite the various advantages of applying fog computing at the edge, fog computing is not needed for every IoT and IIoT application. Here are some drawbacks for you to consider whether you need fog computing or not:
- Might cost more at the beginning of the investment
- Fog system is more complex than the edge
- Have more potential points of failure due to the complex system
-
Management process may require more involvement and time compared to traditional centralized workflows
An example of Fog Computing

An excellent example of fog computing is an embedded application within a production line automation. Running automation within a production line will incorporate various IoT devices, sensors, and actuators. These embedded devices can include temperature sensors, humidity sensors, flow meters, water pumps, and more. Then, amid the production line, all of these edge devices and sensors are constantly measuring analog signals based on their specific function. These analog signals are then turned into digital signals by the IoT devices and sent to the cloud for additional processing. In a traditional cloud environment, constant data telemetry can take up bandwidth and experience more latency, a key disadvantage for constantly moving data to the cloud.
Receiving and sending every single second can be overwhelming. However, with an additional fog layer at the edge, the fog server would reduce the traffic by processing and filtering the collected data with a specific parameter to determine if it will need to go to the cloud. Some of the information may not be sent to the cloud at all since the fog layer does have capabilities for processing at its source. Additionally, for more intelligent applications such as machine vision systems, the fog server can be in the form of an AI-enabled rugged computer to manage various high-speed cameras and implement AI inference models for defect detections at the production lines.
Learn More About Rugged Machine Vision Computer for SCADA Systems
Summary – Fog Computing vs Edge Computing
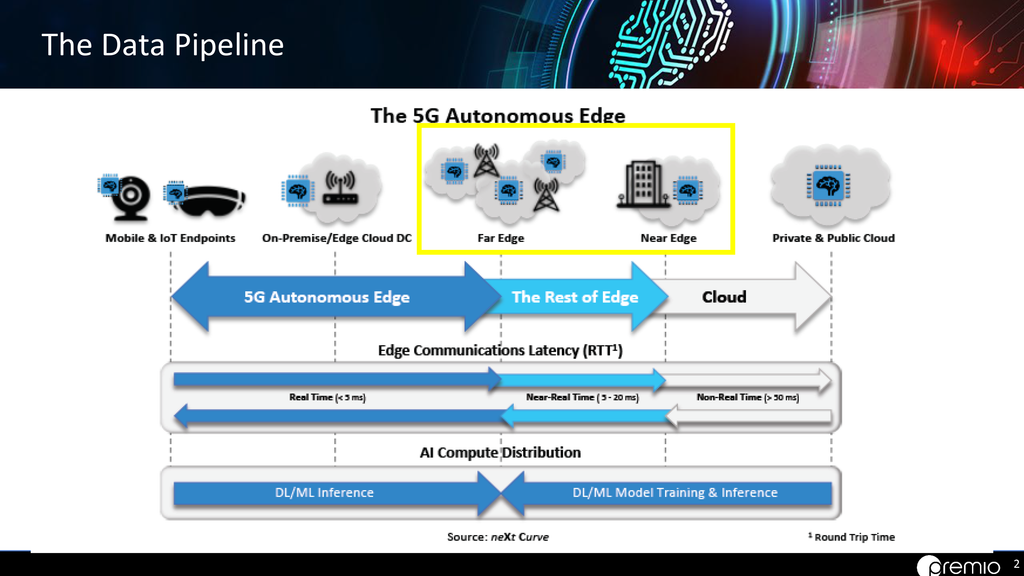
In short, edge computing and fog computing are pretty similar. The main difference is the location of data being processed. Edge computing processes data directly at the source of generation, whereas fog computing may sit further away near a telecommunication network tower. But for each of these models to be possible, specialized hardware is required for both the fog and edge to process, store, and connect critical data in real-time.
Purpose-Built Hardware Designed for the Edge and Fog
AI Edge Inference computer | RCO-6000-CFL Series

The AI Edge Inference computers are specialized industrial hardware built to support real-time processing and inference machine learning at the rugged edge. Purpose-built industrial inference computers can withstand temperature extremes, shocks, vibrations, and power fluctuations. Equipped with powerful CPU, GPU, and Storage accelerators, the AI Edge Inference computers enable real-time inferencing at the edge for mission-critical applications. In addition, the rich I/O features allow the AI computer to communicate with multiple IIoT devices and sensors.
Key Features:
- Intel® 9th Gen CFL S Processor & Q370 Chipset support up to 8 Cores
- Modular EDGEBoost Nodes to support hardware acceleration
- NVMe SSDs Storage Bricks
- GPU, TPU, and M.2 acceleration support
- 5G Ready
- Flexible I/O for More I/O: LAN, USB, and 10 GbE
- Power Ignition Management
- Industrial-Grade Ruggedized Design
Applications:
- Industrial Automation
- Machine Vision Systems
- Rugged Edge Computing
- NVR Surveillance
- DPU Server Acceleration
- Mining Automation
- Vehicle Telematics
Learn More About the AI Edge Inference Computers
DPU Accelerated Server - FlacheStreams

FlacheStreams DPU (data processing units) server is an accelerated rackmount server designed to provide high-performance computing on the fog layer. This server is purpose-built for complex data center workloads on public, private, and hybrid cloud models. DPU accelerated server combines the latest CPUs, GPUs, DPUs, and FPGAs for performance-driven scale-out architecture on the fog layer. With DPU on the fog layer, the host server can free up its precious CPU resources by offloading some processes to the DPUs. The host server then can allocate its CPU resources to other mission-critical applications. For instance, some of the benefits of implementing DPU servers on the fog layer is the ability to accelerate networking, storage, and security management functions directly on the network interface card.
Key Features:
- Up to Dual Intel Xeon or AMD EPYC CPUs (up to 240W each and 128 cores)
- Supports up to 18 DPUs accelerators
- Up to 36x 25Gb/s Network Accelerator Ports
- 2x 96lane PCIe Switch Board for Peer-to-Peer Communication
- Up to 300 TB of NVMe SSD Storage
- RoHS 6/6 Compliant
Learn More About DPU Accelerated Servers
Why Premio?
Premio is a global solutions provider that has been designing and manufacturing top-notch industrial computers for over 30 years in the United States. Our solutions are designed to operate reliably and optimally in the most challenging environmental conditions. Premio provides expertise in designing, engineering, and manufacturing (ODM) of ruggedized edge computers and server hardware for key enterprise markets. In addition, Premio offers a variety of industrial edge computers and high-performance DPU servers for IIoT applications. Contact us for edge and fog hardware computing solutions. One of our industrial computing professionals will assist you with your edge computing and fog computing hardware based on your specific needs.
